원문링크 :
Program to Construct a Binary Search Tree and Perform Deletion and Inorder Traversal - javatpoint
Program to Construct a Binary Search Tree and Perform Deletion and Inorder Traversal on fibonacci, factorial, prime, armstrong, swap, reverse, search, sort, stack, queue, array, linkedlist, tree, graph etc.
www.javatpoint.com
Data Structure를 공부하면서 Tree 부분이 아직 익숙하지 않아 시행착오를 조금 겪었습니다.
이를 정리하고자 글을 씁니다.
Binary Search Tree란
- node로 이루어져 있다, parent가 없는 첫 노드 root가 존재하고, 모든 node들은 right,left 즉 최대 두개의 child를 가질 수 있는 자료구조이다. int 데이터를 저장하는 경우 node보다 높은 데이터는 right subtree에 낮은 데이터는 left subtree에 저장된다.
struct 구조
|
1
2
3
4
5
|
struct node{
int data;
struct node *right;
struct node *left;
};
|
cs |
Construction
1. 노드를 생성하는 함수를 만든다. c언어로는 struct node에 메모리를 동적할당하고 각 요소 data, left, right를 초기화시킨다.

|
1
2
3
4
5
6
7
8
|
struct node *createNode(int data){
struct node *newNode = (struct node*)malloc(sizeof(struct node));
newNode->data = data;
newNode->right = NULL;
newNode->left = NULL;
return newNode;
}
|
2. Tree에 node를 추가하는 함수를 만든다. 추가하고자 하는 데이터가 기존의 데이터보다 작으면 left subtree로 향하고, 크면 right subtree로 향한다. 언제까지? leaf node가 될 때까지
*leaf node : child가 없는 node
exception : 첫번째 node 즉 root node가 존재하지 않으면 추가하고자 하는 node를 root로 선언한다.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
void insert(int data){
struct node *newNode = createNode(data);
if(root==NULL){
root = newNode;
return;
}
else{
struct node *current = root;
struct node *parent = NULL;
while(true){
parent = current;
if(data < current->data){
current = current->left;
if(current==NULL){
parent->left = newNode;
return;
}
}
else{
current = current->right;
if(current==NULL){
parent->right = newNode;
return;
}
}
}
}
}
|
이 코드 작성하면서 내가 겪은 실수
if문 안의 등호 넣을 때 ==를 =로 작성하는 실수. 주의할것
Deletion
어떻게 해야할 지 감도 잡히지 않았음. 원문을 보니 3가지 경우로 나눠 처리했음. 조금 더 고민했으면 떠올릴 수 있을 것 같음,
앞으로 혼자 고민하는 시간을 더 갖자
case를 나눠서 분석적으로 접근하는 연습.
1. delete하고자 하는 node가 leaf node인 경우
-node를 그냥 없애버림
2. delete하고자 하는 node가 1개의 child를 가진 경우
-해당 node를 child 노드와 교체함
3. 2개의 child를 가진 경우
-해당 node의 right subtree중 가장 작은 값을 가진 node와 교체
delete함수 인수로, node와 data를 받음. ( delete(struct node* node, int data) )
1.인수 node의 data와 인수로 받은 data를 비교하여 delete하고자 하는 node에 도착할 때 까지 함수를 recursively하게 call한다.
2.delete하고자 하는 node에 도착하면 위에서 나눈 경우에 따라 처리한다.
알고리즘을 짤 때 recursion을 활용하는 것이 아직 익숙하지 않음, 자주 시도 해보고 어떤 상황에서 필요한지 몸에 익히고 기록하자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
struct node *minNode(struct node *root){
if(root->left != NULL){
return minNode(root->left);
}
else{
return root;
}
}
struct node *deleteNode(struct node *node, int data){
if(node==NULL){
return NULL;
}
else{
if(node->data > data){
node->left = deleteNode(node->left, data);
}
else if(node->data < data){
node->right = deleteNode(node->right, data);
}
else{
if(node->left==NULL && node->right==NULL){
node = NULL;
}
else if(node->left == NULL){
node = node->right;
}
else if(node->right == NULL){
node = node->left;
}
else{
struct node *temp = minNode(node->right);
node->data = temp->data;
node->right = deleteNode(node->right,temp->data);
}
}
return node;
}
}
|
원문에서는 node를 return 하는 함수로 짰지만 void형식으로 짜도 상관없을 것 같음, 실제로 원문 main 함수에서도 delete함수의 return 값을 받아주기만 하고 print는 기존의 root를 이용하여 출력.
코드 15번째 줄의 node->left = deleteNode(node->left, data); recursion
입력받은 node의 data가 입력받은 data보다 크면 node의 left-subtree가 입력받은 data를 가진 node를 삭제한 tree가 되게 하는 recursion 구조. 반대의 경우도 마찬가지.
처음 알고리즘 구상후 코드 짰을 때 겪은 실수.
코드 15번째 줄을 node = deleteNode(node->left, data); 이렇게 짰음.
아직 recursion으로 함수를 call했을 때 call이 stack으로 쌓이는 것이 머릿속으로 심플하게 이해되지 않고, return값이 어떻게 될 것인가 혹은 return 값의 순서 등을 파악하는 것이 능숙하지 않음
그렇기에 알고리즘을 짤 때 recursion을 활용하는 것에 부담을 느낌. 조금의 연습이 필요할듯. 연습하면 된다.
알고리즘 짤 때 미리 정리하고 짜고, 왠만하면 오류없이 한 번에 실행 될 수 있게 주의를 기울여 짜기 (잔실수 용납X)
In-order traversal (left->root->right)
재귀함수를 사용하여 구현
traverse함수 인수로 node를 받는다고 하자. 함수에서 traverse하여 print한다고 했을 때 print하기 전에 먼저 node->left를 인수로 하는 traverse함수를 call하고 그다음 data를 print하고 그 뒤 node->right 를 인수로 하는 traverse함수를 call
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
void inOrdertra(struct node* node){
if(root==NULL){
printf("Tree is empty\n");
return;
}
if(node->left!=NULL){
inOrdertra(node->left);
}
printf("%d ",node->data);
if(node->right!=NULL){
inOrdertra(node->right);
}
return;
}
|
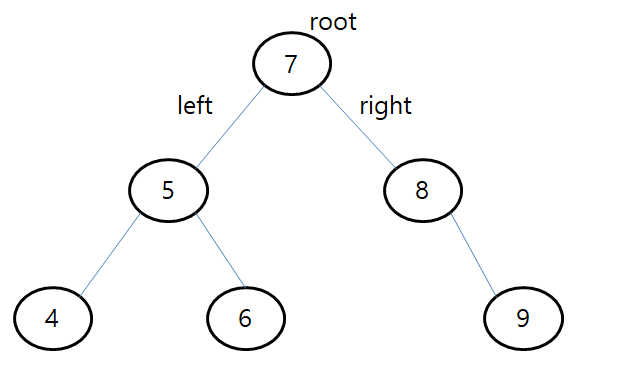
위 함수에 위의 트리를 넣었다고 가정하면 inOrdertra(root)
process
1.첫 if문 if(node->left!=NULL)에 걸려서 inOrdertra(node->left);
node->left는 5라는 데이터를 가진 node
2. 위에서 call된 함수가 또 첫 if문에 걸려서 inOrdertra(node->left);
여기서 node->left는 4라는 데이터를 가진 node
3.left child가 없기때문에 print(4)가 실행
4.stack에 쌓여있던 5라는 데이터를 가진 node 의 function call에서 print(5) 실행
5.이후 그 아랫줄의 if에 걸려 inOrdertra(node->right);
node->right는 6이라는 데이터를 가진 node
6.위의 node function call에서 print(6)가 실행(child가 없기 떄문에 다른 if에는 걸리지 않음)
7.stack에 쌓여 있던 7이라는 데이터를 가진 node의 function call에서 두번째 코드인 print(7)실행
8.이후 그 아랫줄의 if에 걸려 inOrdertra(node->right);
node->right는 8이라는 데이터를 가진 node
9.이후 나머지 node들은 left child가 없기 때문에 left child를 인수로 하는 function call if문에는 걸리지 않고
functioncall 해당 node값이 print된 후의 밑의 if(node->right!=NULL) 에 걸려 right child를 인수로 하는 함수를 call한다.
결과적으로 출력순서는 아래와 같다.
4 5 6 7 8 9
recursion에서 function call 이 stack형식으로 쌓이는 것을 이해 한다면 위 process로 이해하는 데 어려움이 없을 것이다.
recursion을 알고리즘 구현에 활용하려면 한 단계 더 높은 이해를 요구하는 것 같다. 더 많은 케이스를 접해보고 연습하자.
핵심 키워드
1. 알고리즘 구상시 CASE 분류 분석적 사고
2. RECURSION 활용하여 알고리즘 구현
'Programming > DataStructure' 카테고리의 다른 글
| [자료구조] Program to determine whether two trees are identical (0) | 2020.03.10 |
|---|---|
| [자료구조] To convert Binary Tree to Binary Serach Tree (0) | 2020.03.04 |
| for문 vs while문 linked list sorting할 때 코드 차이점(가시성) (0) | 2020.02.26 |
| [자료구조] Display Circular Linked List in Reverse Order. (recursive call) (0) | 2020.02.25 |
| [자료구조] To Create circular linked list and count . (feat. do-while) (0) | 2020.02.25 |


댓글